Reinforcement Learning
Behavior Cloning
2.3.2
The training loss is plotted below with default hyper parameters (notice the log scale on the x axis).
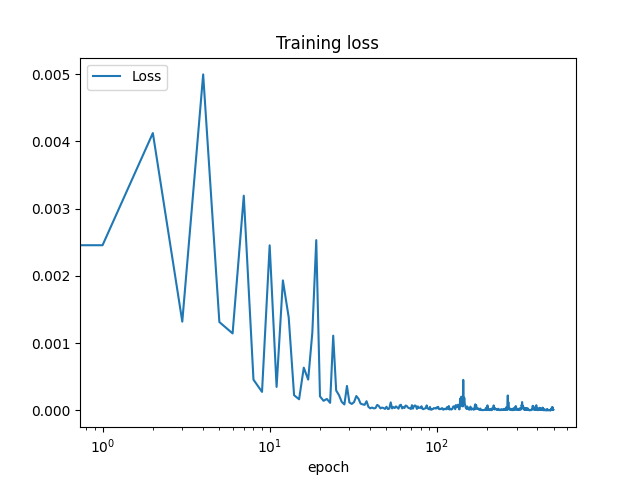
Success rate: 0.26
Average reward (success only): -8.10973200508584
Average reward (all): -9.68583188504118
2.3.3
I chose to experiment by changing the number of epochs and observing the success rate. I expected to see a "negative parabola" shape where success rate peaked in the middle, with the lower epochs and higher epochs having a lower success rate due to under training and over training, respectively. I saw this just to an extent:
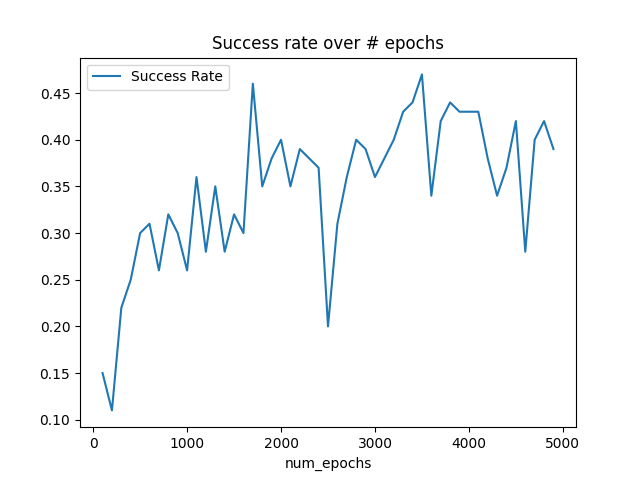
However I expected the dropoff to occur more steeply.
Dagger
3.3.2
I plotted the loss of each epoch separately; one can see in this graph that earlier epochs look like a typical downward trend, but later epochs already start off with low loss.
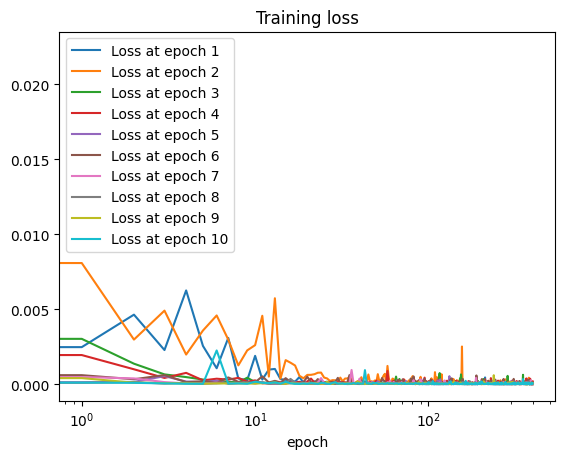
Success rate: 1.0
Average reward (success only): -4.100944236231891
Average reward (all): -4.100944236231891
3.3.3
The average reward and success rate is much higher than the behavior cloning policy. This makes sense because as the dagger iterations go on, the dataset is amended with more relevant training data, by querying the policy for observations and the expert for respective actions.
3.3.4
I varied the batch size and observed both the success rate and average reward. First, I started with batch sizes as low as 2, however this caused the runtime to explode and take way too long, so instead I started with 16 and went up to 256. The results are below.
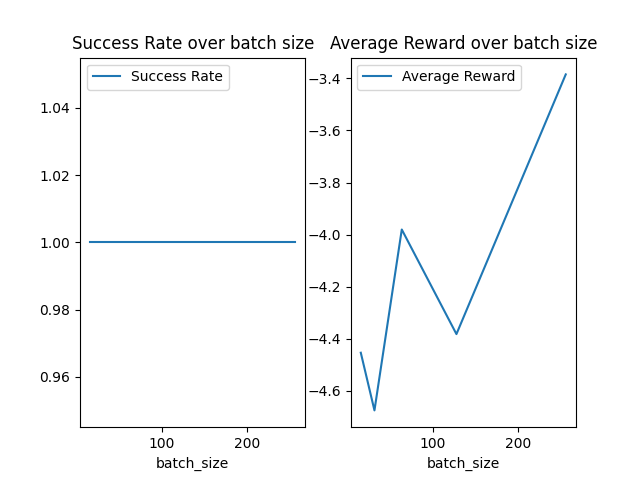
As you can see, the success rate was still 100% across all batch sizes. Average reward oscillated but generally increased with batch size.
Policy Gradient
4.3.2
The training loss is plotted below with default hyper parameters.
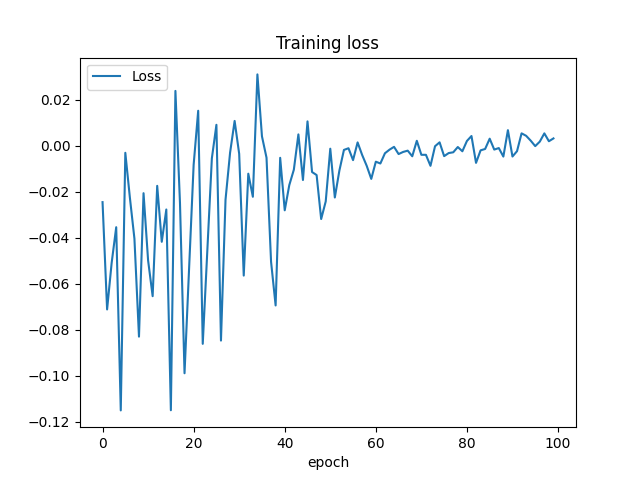
Success rate: 0.95
Average reward (success only): 200.0
Average reward (all): 199.01
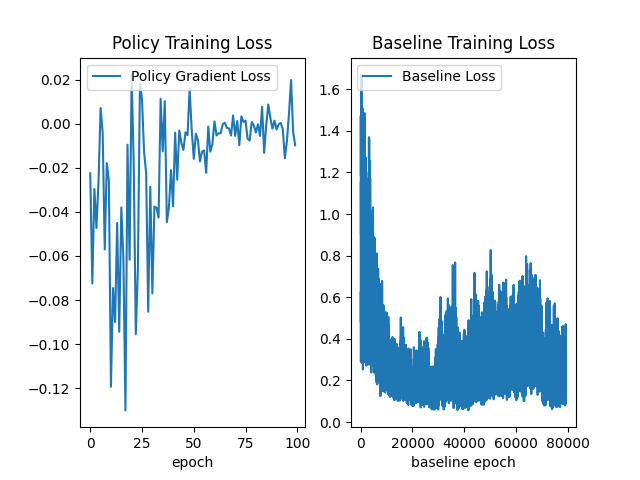
Addendum: after seeing the Ed post about posting baseline training loss as well, I made the combined plot below. (Notice the number of epochs is greater for baseline, since there's a training loop for baseline within each of the outer policy gradient epochs.)
4.3.3
I chose to experiment with the discount rate $\gamma$, since that one has the most meaningful interpretation to me. I expected to see lower success rates for low values of $\gamma \in [0, 0.5]$, since those values closer to zero will drastically devalue future rewards, and did not know what to expect for $\gamma = 1$, where future rewards are all valued just as equally as the current reward. The results were surprising:
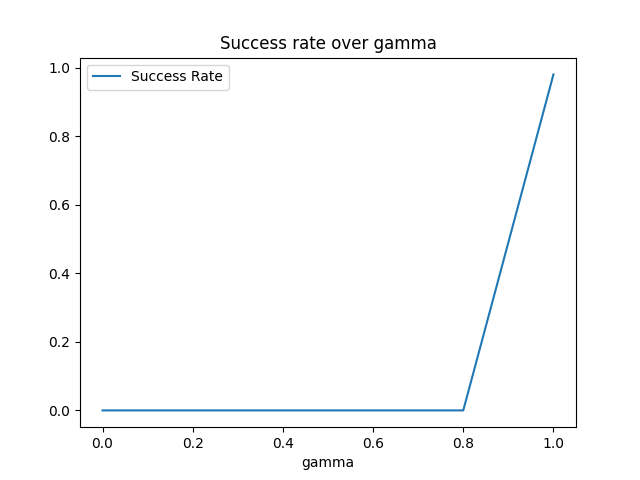
The success rate was zero for $\gamma \in {0, 0.2, 0.4, 0.6, 0.8}$ and one for $\gamma = 1$. I find it surprising that there wasn't any more variation or any success rates between 0 and 1.